Socorro/Tecken Overview: 2022, presentation
Socorro and Tecken make up the services part of our crash reporting system at Mozilla. We ran a small Data Sprint day to onboard a new ops person and a new engineer. I took my existing Socorro presentation and Tecken presentation [1], combined them, reduced them, and then fixed a bunch of issues. This is that presentation.
Socorro/Tecken Overview: 2022
Title slide

Socorro and Tecken: Overview of crash ingestion (2022)
Hi! I'm Will Kahn-Greene. I work on the Socorro project, the Mozilla crash ingestion pipeline, and it's jaunty sidekick Tecken project which covers symbols services.
This presentation is a high-level overview of Socorro and Tecken covering:
What are Socorro and Tecken
Some things in the domain of crash reporting and crash ingestion that are nice to know like symbols, minidumps, Breakpad, signatures, and so on
Rough architecture
Some fun facts about crash data
Where to learn more
I hope this is helpful! If you see mistakes, please let me know.
Slide 1

Section: Crash ingestion at Mozilla
First, let's talk about the big picture of crash reporting at Mozilla and how crash ingestion fits into it.
Slide 2

Mozilla's crash reporting infrastructure is vast.
Crash reporting is a critical part of building products. All products have some kind of crash reporting. The infrastructure for supporting crash reporting is intricately tied to everything from development to building to testing to release.
Slide 3

Multiple tools in Mozilla's crash reporting infrastructure.
Crash reporting consists of a whole bunch of tools that run in different places in order for everything to work.
It starts in the build system where after compilation, dump_syms runs on the binaries extracting symbols and building sym files.
Then the symbol uploader scripts package up all those files into a zip file and upload it to the Mozilla Symbols Server
Mozilla products include a crash reporter which kicks in when a process has crashed or for an unhandled exception. Crash reporters capture information about the crash, package it up, and submit it to the crash ingestion pipeline. Crash reporters are complicated. Some products have multiple crash reporters.
Stackwalkers which parse minidump files and unwind the stack. Some of the stackwalker also symbolicate the tack. We have multiple stackwalkers at Mozilla that run in different contexts. The one that runs in Socorro is from rust-minidump
Slide 4

Multiple services in Mozilla's crash reporting infrastructure.
The Mozilla Symbols Server handles symbol uploads, storage, and downloads.
The Mozilla Symbolication Server uses symbol files to symbolicate memory addresses in symbolication API requests.
The crash ingestion pipeline accepts crash reports submitted by crash reporters in the product, stores the crash reports, processes crash reports, and makes the crash information available for search and analysis.
The data pipeline accepts incoming Telemetry data. One of the kinds of telemetry data we collect is crash pings. The data pipeline collects crash pings, stores them, processes them, and makes processed crash ping information available for analysis.
Slide 5

Role of socorro-eng.
"socorro-eng" is the name of the GitHub team that owns the repositories on GitHub for Socorro and Tecken. Generally, the team doesn't exist in the Mozilla org chart.
Prior to a couple of months ago, it was me (engineer) and Jason (ops).
Now--and the reason for updating the presentation for onboarding people--it consists of me (engineer), Eduardo (engineer from a different team that spends part of his time on socorro-eng things), and Harold (ops).
Anyhow, the "team" is responsible and maintains these parts:
Mozilla Symbols Server and Mozilla Symbolication Server (Tecken)
the crash ingestion pipeline (Socorro)
Internally to the team, we have a bunch of other code names for things. We've got "Antenna" which is the collector of the crash ingestion pipeline. We've got Eliot which is the Mozilla Symbolication Server webapp. We've got the socorro-submitter which is the AWS Lambda job that re-packages and submits 10% of incoming crash reports to the Socorro stage environment.
We've got several repositories of tests and load tests. We've also got an AWS signing proxy and a GCP signing proxy.
We monitor the systems, keep them running, and update them constantly in response to changes in dependencies, services, and requirements.
We consult with teams putting out new products that need crash reporting.
We consult with teams looking at product health data. We work with the Release Engineering, Stability, and Crash Reporting Working Group groups.
Further, we investigate issues, write up bugs, coordinate with responsible teams, and in some cases fix issues in other parts of the crash reporting infrastructure.
Slide 6

Let's start with Tecken.
Let's focus a bit and talk about Tecken first.
Slide 7

What even is Tecken?
Tecken started in 2017 with a few goals. First, we wanted to rewrite Snappy which supported downloading symbols from the AWS S3 bucket we stored symbols in. Snappy wasn't built in a way that made it easy to set up in the cloud and scale horizontally. That's cool--no biggie. Second, we wanted to reduce the scope of Socorro to just crash ingestion. At the time, Socorro include the symbols upload API, access controls, and other symbols-related bits. Third, we wanted to write a new symbolication API which would use the symbols files in the AWS S3 bucket to look up memory addresses and get back symbol information.
Tecken was a single webapp that handled all these things: upload API, download API, symbolication API, and access controls. Last year, I split out the symbolication API into a separate service.
So now we have "Tecken" which is two different services:
Slide 8

What is a symbol?
Tecken is the system that does symbols things--but what's a symbol?
Slide 9

Explanation of symbols.
"Symbols?! We don't need no stinking symbols!"
Well, yes. Yes we do.
Mozilla builds software products. The build process generates binaries which we package up and ship as released products. One build step in the build process takes debugging binaries, extracts symbol information using dump_syms, packages it in a sym format, and then uploads that to the Mozilla Symbols Server using a symbol uploader script.
An entry in the sym file for a symbol tells us something like this:
This thing in memory starting at this byte corresponds to function JammyJamJam on line 200 in source file jampocalypso.c.
That's pretty helpful!
Slide 10
More about sym files.
The Breakpad project defines the sym file format.
The inability to symbolicate inline functions is covered in a few bugs including [bug 1636194].
Slide 11

Creating an example sym file.
It's pretty neat that you can do this in Rust. The equivalent-ish thing in C is something like this:
Slide 12
Example sym file.
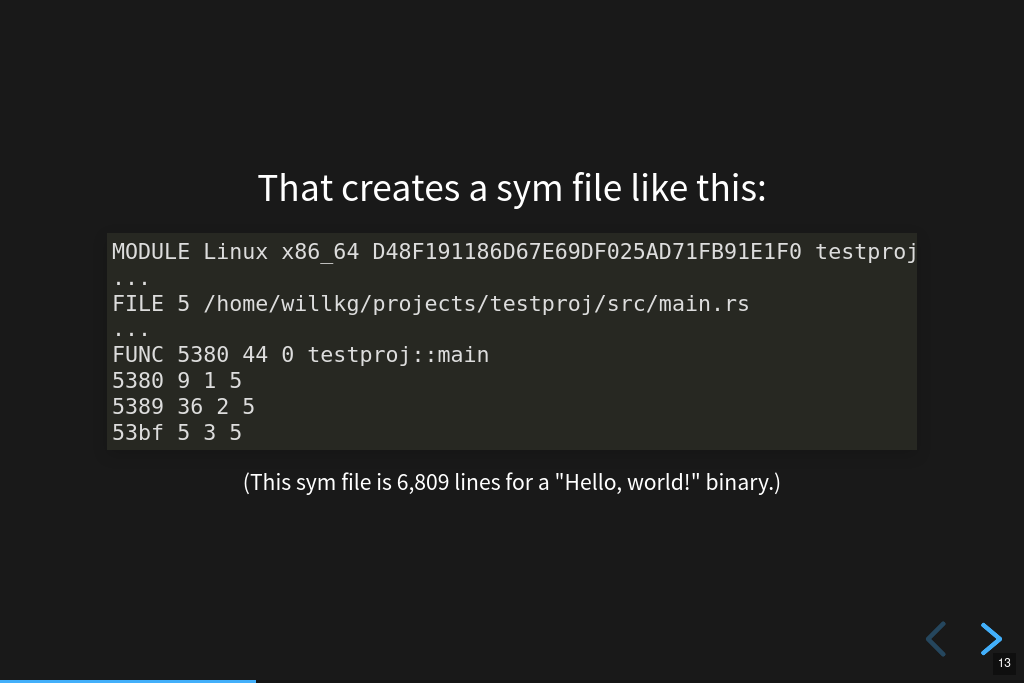
The sym file for the C program we created is shorter. This is the entire thing:
MODULE Linux x86_64 8FB2C79253F40FF0A4269F7A967EF1EE0 helloworld INFO CODE_ID 92C7B28FF453F00FA4269F7A967EF1EE80255E5A FILE 0 /home/willkg/hello/helloworld.c PUBLIC 1000 0 _init PUBLIC 1060 0 _start PUBLIC 1090 0 deregister_tm_clones PUBLIC 10c0 0 register_tm_clones PUBLIC 1100 0 __do_global_dtors_aux PUBLIC 1140 0 frame_dummy FUNC 1149 23 0 main 1149 8 3 0 1151 14 4 0 1165 5 5 0 116a 2 6 0 PUBLIC 116c 0 _fini STACK CFI INIT 1060 26 .cfa: $rsp 8 + .ra: .cfa -8 + ^ STACK CFI INIT 1020 20 .cfa: $rsp 16 + .ra: .cfa -8 + ^ STACK CFI 1026 .cfa: $rsp 24 + STACK CFI INIT 1040 10 .cfa: $rsp 8 + .ra: .cfa -8 + ^ STACK CFI INIT 1050 10 .cfa: $rsp 8 + .ra: .cfa -8 + ^ STACK CFI INIT 1149 23 .cfa: $rsp 8 + .ra: .cfa -8 + ^ STACK CFI 114e .cfa: $rsp 16 + $rbp: .cfa -16 + ^ STACK CFI 1151 .cfa: $rbp 16 + STACK CFI 116b .cfa: $rsp 8 +
Slide 13

Hwat are sym files good for?
Let's talk about what we use sym files for.
Slide 14
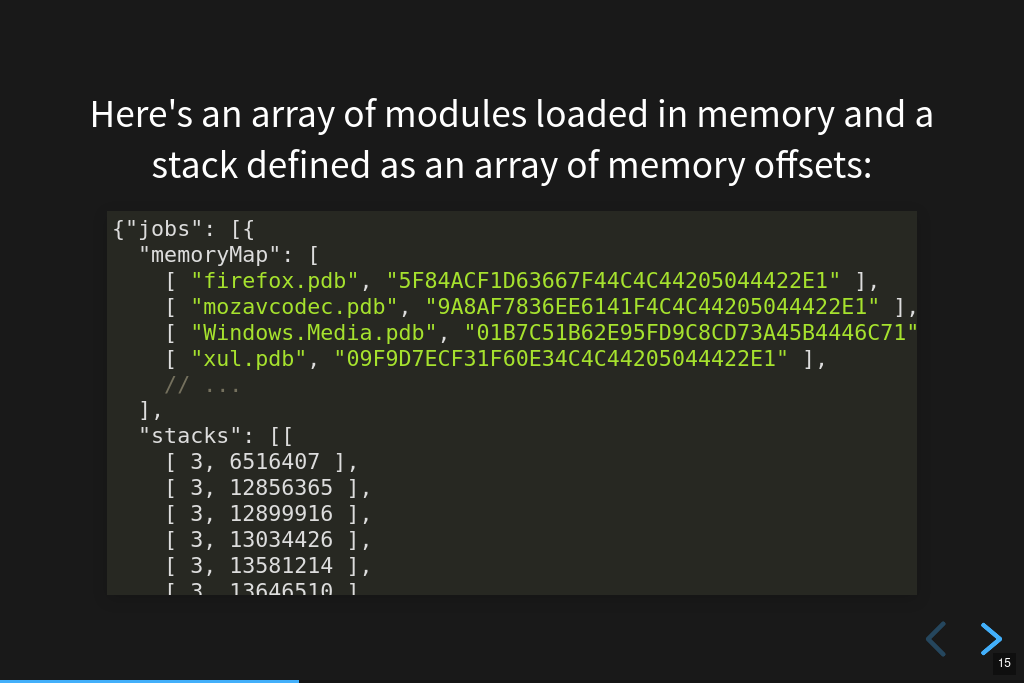
Symbolication request.
The Mozilla Symbolication Server has a symbolication API and this is an example of that. It consists of a list of modules denoted as "debug filename" / "debug id" pairs. Using those, this symbolication request wants to get back the symbols for a set of memory addresses.
Slide 15
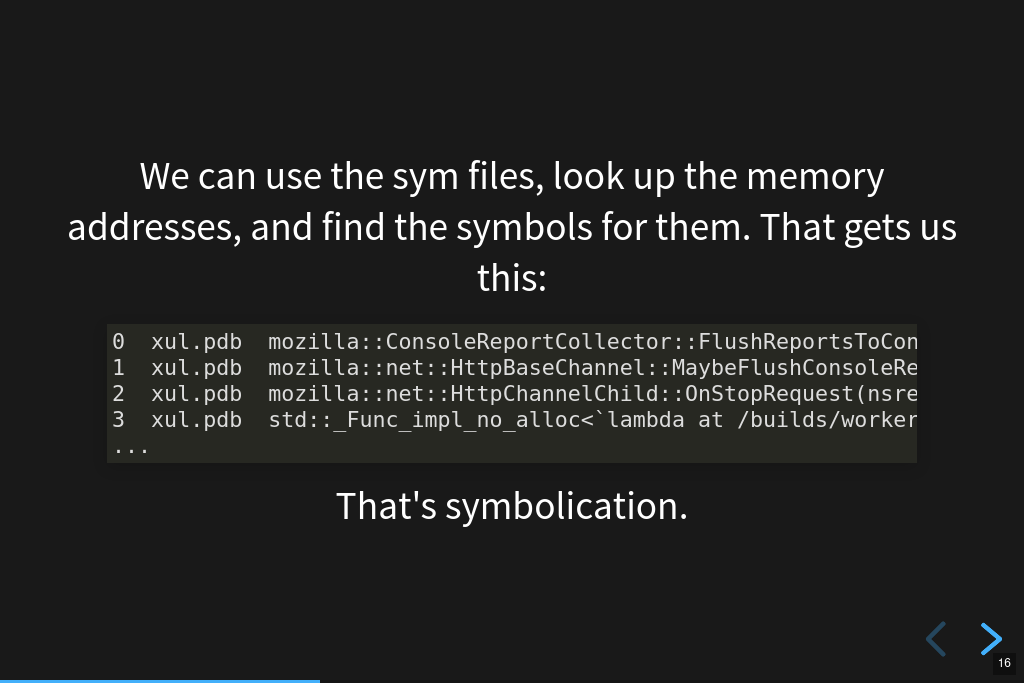
Symbolication.
We can download the sym files generated during the build for those debug filename / debug id pairs, look up the memory addresses in them to determine what function they belong to, and then emit the symbol information.
In this example answer, we see the module name and the symbol. We also know the line number, the source file, and some other things.
That's the gist of symbolication.
We use sym files for symbolicating in a variety of ways:
unwinding and symbolicating the stack in the crash ingestion processor
symbolicating memory addresses in the Firefox profiler
getting back rich stacks when using debugging tools
emitting symbolicated stacks after crashes in tests
Slide 16

Let's talk about the service architecture.
Slide 17

Two services.
The Tecken project is composed of two services:
Mozilla Symbols Server (https://symbols.mozilla.org/) which is code-named Tecken (which is a little confusing).
Mozilla Symbolication Server (https://symbolication.services.mozilla.com/) which is code-named Eliot [2].
Slide 18
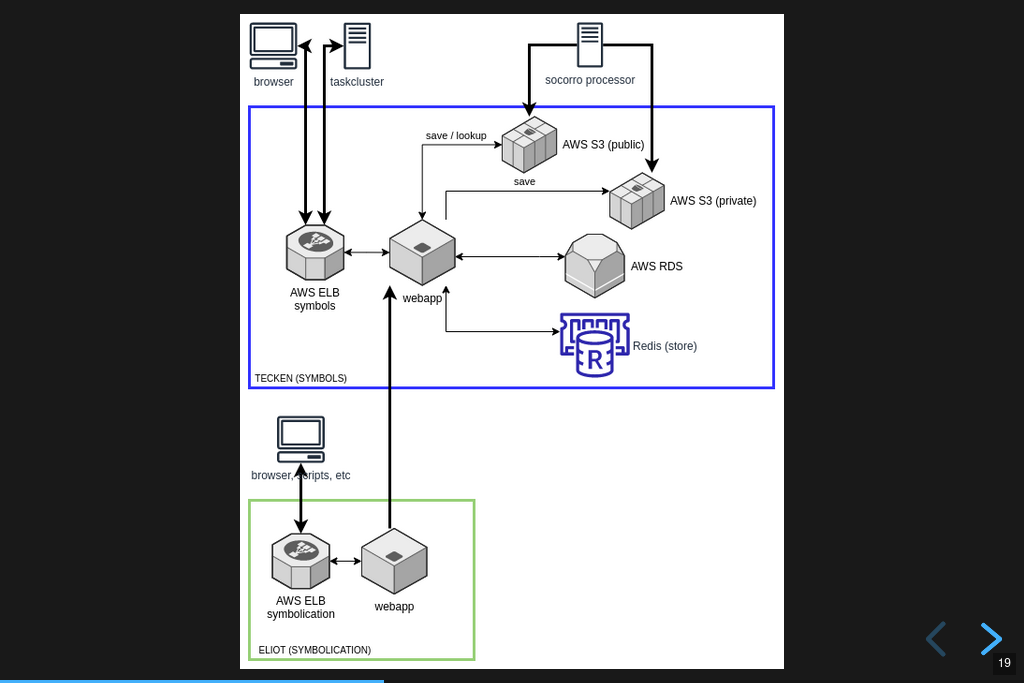
Infrastructure diagram.
Here's a rough architecture diagram for Tecken (the project). At the time of this writing, this diagram isn't entirely correct--there are still some things that exist, but don't show up in this diagram. There are tickets to remove them. As time moves forward, hopefully the diagram gets closer to reality.
Anyhow, what we do see here is a service in a blue rectangle and a service in a green rectangle.
The blue rectangle is the Tecken webapp which comprises Mozilla Symbols Server. It's a boring Django webapp. It stores symbol data in AWS S3. It has a Postgres database (AWS RDS) for bookkeeping. The webapp scales horizontally based on demand.
The interesting thing here is that the Socorro processor doesn't use the downloading API in the webapp to download symbols--it accesses them directly. That's incredibly naughty. Fixing that is complicated and is covered in [bug 1560176]. I need to get to that soon.
Another interesting thing here that isn't clear is that the AWS S3 bucket in question is owned by another account that's not really associated with this service. The bucket has so much data in it, it'll take both a lot of time and a lot of money to move it. I started working on a migration plan, but then we decided we're switching cloud providers, so I'll work it out as part of that project soon.
The green rectangle is the Eliot webapp which comprises Mozilla Symbolication Server. It's a boring Falcon webapp. It doesn't do any bookkeeping, so it doesn't need a database. It downloads sym files using the downloading API in Mozilla Symbols Server. That way we keep track of which symbol files we're missing.
One thing that doesn't show up in the diagram is that Eliot uses symbolic for parsing sym files and doing symbol lookups. I talk a bit about that in Experimenting with Symbolic. I started a blog post as a retrospective of the Eliot project. I'll finish that up soon.
Slide 19

Mozilla Symbols Server.
The Mozilla Symbols Server does three things:
- Upload API
-
The upload API which is used by the Mozilla build system, symbol uploaders scripts, Linux packagers, and some other things.
The uploading API is pretty straight-forward. It requires an auth token to use. You upload ZIP files containing a directory hierarchy of sym files.
Over time, sym files have gotten bigger and we're hitting the upper bound of what Tecken can handle without timing out forcing the upload to restart. Fixing that is covered in [bug 1595365]. That's in the list of things to look at soon.
- Download API
-
The download API which is used by anything doing symbolication, the Firefox profiler, debuggers, and other things.
The downloading API matches the Microsoft Symbols Server.
- Webapp for debugging
-
The webapp is where you set up auth tokens for uploading. It's also where we can see the bookkeeping so we can debug symbol upload and store issues.
Slide 20

Mozilla Symbolication Server.
The Mozilla Symbolication Server does only one thing: it symbolicates.
There are two supported versions of the symbolication API:
v4: This was deprecated years ago when we came up with v5. Even so, it's still in heavy use. The work to migrate users off of it and remove it is covered in [bug 1475334]. That's in the list of things to do soon. I'm hoping that spending zero time fixing issues with this API will eventually cause users to switch to the new one.
-
v5: This is the current version of the API. I've been tweaking it and improving it in backwards-compatible ways over the last year. For example, the original v5 didn't support line numbers, but it does now.
Because of the pain of migrating everything off of v4 [3], I'm avoiding creating a v6.
The Mozilla Symbolication Server is still pretty new. I stood up this service in October 2021. Prior to having a separate server, the symbolication API was one of the things that the Tecken webapp did.
Thus not only are we trying to migrate users from v4 to v5, but we're also trying to migrate them from old server to the new one.
Slide 21

Use cases.
Tecken is used for a bunch of things, but the users primarily fall into two groups:
scripts and bots
engineer types
Tecken is effectively an engineering service focusing on Mozilla's needs.
Slide 22

Let's talk about Socorro.
Slide 23

Some things about Socorro.
Socorro is one of the longer-running projects at Mozilla.
I've worked on it since the beginning of 2016.
Slide 24

What is a crash report?
Crash reports are what it's all about.
It's got two kinds of things in it:
key/value pairs which we call crash annotations
files like minidumps and memory reports
Most of the crash annotations are documented in CrashAnnotations.yaml.
We have a complicated process for adding new crash annotations which is documented in the Socorro docs on crash annotations.
Slide 25

What's a minidump?
The minidump format was defined by Microsoft. They're much smaller than core dumps and have some other properties making them convenient to use for crash reporting.
We use the Breakpad library to manipulate minidump files and more recently, a set of libraries written in Rust like rust-minidump.
Slide 26

What's Breakpad?
Breakpad is a project started by Google in 2006 for crash reporting. It consists of a set of client and server components covering extracting process information, packaging it, submitting it, and processing it. It defines the sym file format for symbol information generated at the time the software was built and used by the stackwalker to unwind and symbolicate the stack.
Mozilla has an ongoing project to rewrite the parts of Breakpad that we use in Rust. One of the more recent steps was swapping out the Breakpad-based minidump-stackwalker that Socorro used for rust-minidump written in Rust.
Slide 27

What are crash reports good for?
A crash report represents the state of a process at the moment that it crashed. The crash annotations tell us details about the process, the computer it's running on, and what the crash was. The minidumps tell us about the state of the process itself like the CPU registers, bits of memory, and the stack.
We look at crash reports to glean information about what went wrong so that we can fix it.
We look at groups of crash reports to help us prioritize things to look at.
Slide 28

What is Socorro's architecture?
Slide 29

Socorro is a collection of services and other things.
The Socorro project consists of a bunch of different parts.
Like any data ingestion pipeline, Socorro has a collector that handles incoming crash reports and a processor that processes them. There's a set of data storage destinations that store crash data in various ways. There's a webapp called Crash Stats for searching, faceting on, and analyzing crash data.
In addition to that, there's a scheduled task runner, a bunch of libraries and tools for using crash data, and a bunch of project infrastructure for testing, deploying, debugging, and maintaining Socorro.
It's predominantly written in Python, but there's a lot of Bash, some JavaScript, and even some Rust and Go.
Slide 30
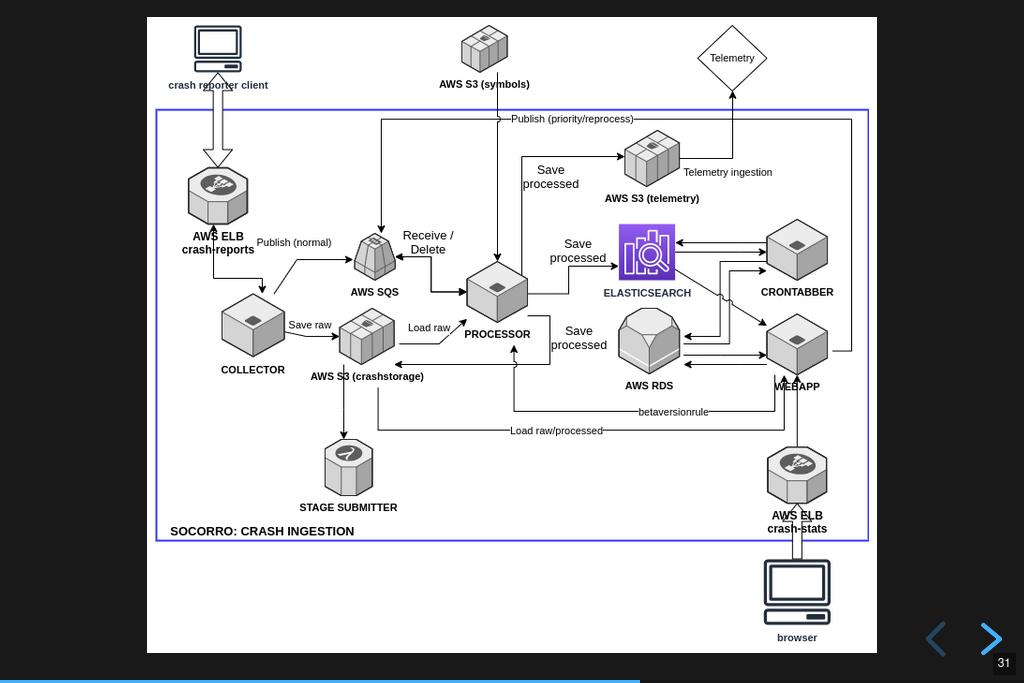
Infrastructure diagram.
Socorro is a system with a lot of parts. It might look complex, but that's probably because I don't do diagrams very well [4].
The gist of it is that this is an ingestion pipeline and most of the parts are related to the flow:
crash reports are submitted by crash reporters to the collector
the collector saves the crash report information to AWS S3
the collector adds the crash id for the crash report to the processing queue in AWS SQS
some short time later, the processor retrieves the crash data from AWS S3
the processor processes the crash report using a sequence of rules
the processor saves the processed crash data in AWS S3 and Elasticsearch
Then we have the webapp (Crash Stats) which lets you view crash data and search it.
We also have crontabber which is the name of the scheduled task runner which runs periodic maintenance tasks.
There's a stage submitter which takes crash data from the production environment, packages it up as a crash report, and submits it to the stage environment.
Slide 31

Let's talk about some fun facts!
These are facts. Fun facts!
Slide 32

Fun fact 1: crashes result in a crash ping and a crash report and they're different!
Fun fact 1: crashes result in a crash ping and a crash report and they're different!
When Firefox crashes, the crash reporter assembles a crash ping and a crash report and they're different.
- Crash pings
-
Crash pings are part of the Telemetry data set, so collection is governed by Telemetry-related preferences which default to "on".
The data that makes it into a crash ping is the set of annotations in CrashAnnotations.yaml marked with ping: true. Note that it's a subset of all possible crash annotations and limited to category 1 and 2 [5] kinds of things. The crash reporter walks the stack and sends a list of memory addresses to the functions on the stack. It doesn't include the other frame data or any heap data.
Crash pings are interesting for crash counts, but they're missing a lot of detail you'd need to debug most kinds of crashes.
Not all of Mozilla's products generate crash pings. Firefox and Fennec (the old Firefox for Android) do, but none of the others.
- Crash reports
-
Crash reports are a separate data set that are collected, processed, and stored in the crash ingestion system we call Socorro.
Crash reports are composed of crash annotations, minidumps, and memory reports like we talked about earlier.
Firefox does not send crash reports by default. It asks the user for permission to send a crash report every time. There is a permission to send backlogged crash reports on your behalf, but this defaults to off.
Crash reports contain category 1, 2, 3, and 4 data so we limit how much we collect, limit how long we keep it for, and restrict who can see it.
Because it has more details about the state of the process when it crashed, it's good for debugging crashes.
Not all crash reports make it to Socorro. Some products don't send crash reports to Socorro at all. Some crash reports for products that do send crash reports to Socorro never make it to Socorro.
Slide 33

Fun fact 2: the collector throttles crash reports.
Fun fact 2: the collector throttles crash reports.
We don't want all possible crash report data. We want to collect and store as little data as possible, specifically we try to only collect and store crash report data that's actionable.
We don't want crash report data for products we don't make or for releases that are no longer supported.
We don't want 1,000 crash reports of the same problem when 10 would do.
The collector has a throttler with a set of rules for determining whether to accept a crash report to store and process or to reject it.
You can see the rules at https://github.com/mozilla-services/antenna/blob/main/antenna/throttler.py.
Slide 34

Fun fact 3: crash reports are big!
Fun fact 3: crash reports are big!
"Big" is a relative word. Compared with Telemetry ping data, they're enormous. Stack overflow crashes can be > 25mb. Generally, they average 600kb.
Because of the big-ness, we have to save them to AWS S3 and then pass around a crash id in the processing queues.
Also, sometimes the crash report is big enough that the crash reporter times out while trying to submit the crash report. The crash reporters handle this situation by keeping crash reports around and trying again later.
Slide 35

Fun fact 4: we reprocess crash reports regularly.
Fun fact 4: we reprocess crash reports regularly.
A lot of crash ingestion is a honing exercise. We fix things in signature generation or upload missing symbols or fix a bug in stackwalking and then we want to reprocess the affected crash reports. This results in better stacks and better crash signatures.
Depending on how the infrastructure evolves, we may need to drop this ability or maybe radically adjust it somehow.
Slide 36

Let's talk about crash signatures.
Slide 37

What's a crash signature?
The socorro processor generates a crash signature for every crash report.
The crash signature algorithm is unique to Socorro. However, there are other crash data sets at Mozilla. For example, crash pings are crash data with stacks and some of the crash annotations and it'd be great to generate Socorro-style crash signatures for crash pings so we could bucket them [6]. I want to work on that soon.
There's also a bug for producing Socorro-style crash signatures in mozcrash. That's in [bug 867571]. Then we could see if crashes that happen in our test infrastructure are also happening to our users.
There's a fuzzing system that has its own crash ingestion pipeline. It'd be great if they could generate Socorro-style crash signatures so they could see if those issues are happening to our users.
So on and so forth. Having a common algorithm for generating crash signatures can help us quite a bit.
Slide 38

Examples of crash signatures.
This is a handful of crash signature examples. Generally crash signature generation walks the stack adding frames one-at-a-time depending on whether the frame is "interesting". Then it prepends some tags for certain kinds of crashes. For example, crashes from "out-of-memory" errors get "OOM" prepended.
The parts of a crash signature are delimited by |.
Sometimes the symbol for a frame is so long [7], so we truncate.
Sometimes symbols differ from platform to platform, so we normalize them.
Slide 39
Crash signatures are fickle.
Crash signatures are fickle and we tune them over time usually in spurts. The algorithm changes over time. Because of this, it's tricky to create a good way to export the crash signature generation algorithm without creating a ton of maintenance work for everyone.
Slide 40

Crash pings and crash reports
I don't remember what I said at this slide. I might have just read it and moved on. In my mind, when I see this, I think of all times I've talked about these data sets and how I'm constantly wrong about them.
I wrote a blog post Crash pings (Telemetry) and crash reports (Socorro/Crash Stats) back in July 2019. I started writing a followup very soon after to correct some of the things in that one. I'm still in the process of writing it. I'll finish it soon.
Slide 41

Both data sets are in telemetry.
We sort of went over this already, but not the part about how both data sets are available in BigQuery.
The crash ping data set is ingested in the data pipeline and ends up in
telemetry.crash.
When the processor processes a crash report and generates a processed crash, it
saves a sanitized subset of that processed crash to an AWS S3 bucket which then
gets picked up by an import job which eventually results in records in the
telemetry.socorro_crash table.
Slide 42

What is crash report data like?
Slide 43

Messy.
Crash report data is messy. The product is crashing for some reason and while the crash reporter does the best it can to capture details about the crashed process and send it to Socorro, it might fail to produce something we can use.
Slide 44
Very messy.
We often get crash reports from computers with bad memory or bad disk. There are some interesting ideas about how to figure this out in the collector so that it could return a response like, "yo--maybe your computer is busted" and then that message could get to the user. That could be pretty cool.
Slide 45

This dataset is POISON.
Crash report data is a toxic data set since it has bits of memory in it.
Slide 46

Data policies.
Crash report data is surrounded by a burrito of data policies. We have:
data collection policy
data access policy
data retention policy
data sharing policy
data storage rules
They unite together to form a Shin Data Jaeger that stands on the wall with its Galaxy Sword to defend crash report data from the horrors of the universe or something something.
Slide 47

The truth is out there.
I did this image ages ago with the intention of making it into a Socorro sticker. I'll do that soon.
Slide 48

Information about things.
This is a bunch of links and things.
This slide has "Questions?" on it, but at this point in the day, I had talked for like 7 hours straight and this presentation alone (and the questions scattered throughout it) took 2 hours. Once we hit this we waved our goodbyes and ended the day.
The word "soon" comes up a lot in this presentation. By "soon", I mean that I have every intention of getting to said thing soon, but it's more realistically not soon because other things have popped up.
If there are things you're waiting on [8], find the relevant bug and gently ping me in it.
El fin
And that's the blogified form of the presentation I did a week ago minus the bits about deploy infrastructure which, while thrilling, aren't all that thrilling outside of a tight-knit community of Socorro-ists.
If the blog post version of the presentation is helpful to you, let me know!